

21 April 2025
April 2025 Benben Update
So, as you may remember, in January I announced that I was planning to port Benben to Common Lisp, and then I upped the schedule for the port in March. Well, it’s a little over a month later, and I figured it was a good time to give you all an update on Benben v0.7.0. A LOT of work has been done in April (a lot more than I thought I did when I first started writing this blog post), including the introduction of a few new features.
So, let’s start looking at things from a birds-eye view. I’ll try to keep each section short. Note that wherever I mention “Benben v0.7.0-dev” or “v0.7.0-dev”, I’m talking about the current (as of writing) Common Lisp code in the Benben source code repository.
The “Original UI” Is Mostly Working Again
Benben’s user interface has been mostly ported over, and is working well enough that I can use Benben v0.7.0-dev as my daily audio player once again. There’s a few things that are still missing, like a couple of missing banner animations, and crashes still happen when something unexpected pops up, but most of the hard work has been finished.
One thing that I did end up changing for v0.7.0-dev is how the banners are displayed. They all have the same overall height now, with smaller banners being placed vertically in the middle of the banner drawing area with some margins around them. This change was done in anticipation of eventually adding a spectrum visualizer or oscilloscope view to the UI.
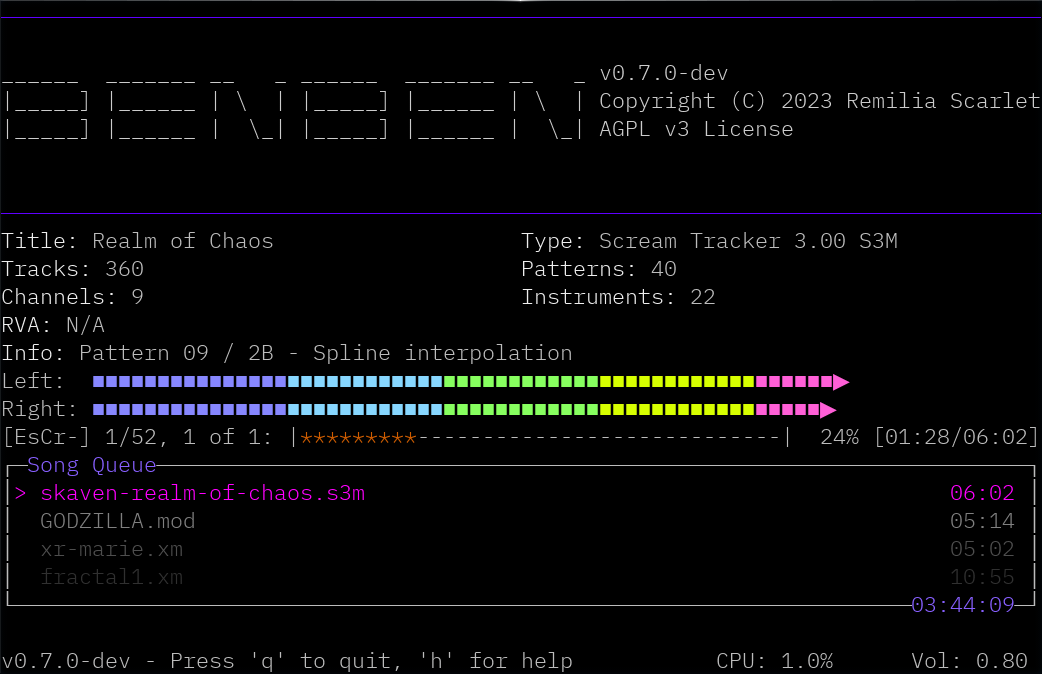
There’s a few additional changes planned as well, including listing the track times a bit differently (time per loop + total time), as well as including an overall running time at the bottom next to the total time.
Now, you may be wondering why I called this the “Original UI”… that’s because…
The New “Minimal” UI
Benben now has two different user interfaces! The Original UI is the one that
everyone knows by now. That one isn’t going away or changing drastically. The
new interface, called the “Minimal UI”, is an ultra-minimalist alternative for
those who wish to simply put Benben in the background and have it use slightly
fewer resources. There’s no colors, no fancy S-Lang stuff, no progress bar, no
VU meters, and no extra ANSI output. Just plain raw text. There’s also no
direct user input with the Minimal UI: you control it entirely from the
remote-benben program. In essence, it lets Benben just become a normal
background program.
Now to be perfectly honest, this started life because I needed to do some intense debugging in Benben of the core internals when I first started the port, and didn’t want to also be debugging the Original UI at the same time. So I wrote this super minimal interface that would let me see basic output, and then control it with my media keys. As it turned out, having such an interface turned out to be useful, so I polished it up and decided to let it exist as an official alternative interface.
This new interface can be selected using the --ui minimal command line option.
The old Crystal version of remote-benben works perfectly fine with the new
Lisp code in v0.7.0-dev, too, so you can use that to control it.
Most Formats Are Working
Support for most of the supported formats has been ported over, with only a few remaining before v0.7.0 comes out. Benben v0.7.0-dev, as of this writing, currently supports these formats:
- VGM (not all chips are supported yet)
- MPEG-1 Layers I, II, and III (.mp1, .mp2, and .mp3)
- Opus
- Module files
- FLAC
- WavPack
- WAV
- Au
- QOA
- Extended QOA Format (see the next section)
That’s about 80% of the formats I tend to support for v0.7.0, so that ain’t a bad start at all. The ones that still need to be ported are:
- Commodore SID
- General MIDI
- Ogg Vorbis
Extended QOA Format
This is not just a new format for Benben, but an entirely new format overall that I’ve been thinking about creating for quite a while. I’ll be introducing it formally in a later blog post, but basically Extended QOA Format (XQA/XQAF) is a new format based on QOA that adds support for metadata, and turns QOA into something usable as an everyday format. It supports Vorbis Comment metadata, as well as explicit support for gapless playback. Audio quality and decoding speeds are identical. Benben will be able to both decode and encode XQA format by the time v0.7.0 is released, but for now, Benben v0.7.0-dev only decodes it.
VGM Library Update
Benben’s VGM support is implemented in a library called SatouSynth, which is the Lisp equivalent to my Crystal library YunoSynth. Both are OOP-ified ports of VGMPlay, designed to turn that code base into a library. SatouSynth is written entirely in Common Lisp, and YunoSynth is written entirely in Crystal (no C bindings for either one).
SatouSynth isn’t as far along as YunoSynth yet, but it will have totally caught up by the time v0.7.0 is done. For now, it (and by extension, Benben v0.7.0-dev) supports these chip emulations:
- Capcom DL-1425 QSound
- General Instruments AY-1-8910 and derivatives
- Hudson HuC6280 (two different cores)
- Irem GA20
- Konami K051649
- Konami K053260
- Konami K054539
- NEC μPD7759
- Namco C140 / Namco 219 ASIC
- Namco C352
- Nintendo NES (APU) and Famicom Disk System
- OKI MSM6258
- Philips SAA1099
- Sega 32x PWM
- Sega MultiPCM
- Sega SegaPCM
- Seta X1-010
- Texas Instruments SN76489 and related
- Yamaha YM2151 (OPM)
- Yamaha YM2203 (OPN)
- Yamaha YM2608 (OPNA)
- Yamaha YM2610 / YM2610B (OPNB)
- Yamaha YM2612
- Yamaha YMZ280B (PCMD8)
Just like in YunoSynth, SatouSynth also supports ZStandard-compressed and BZip2-compressed VGM files. I personally prefer these over GZip-compressed VGMs (.vgz) since they take up even less space, and in the case of ZStandard, decompress faster.
Initial Loading Is Now Done in Parallel
Benben is a bit different from other players in that it pre-scans all of the files it’s going to play ahead of time. This is performed at startup before the user interface is displayed, and is done to provide a much smoother experience later on during playback (and to cache some basic file information in memory).
Older versions scanned files serially, which works, but can be a bit slow at times since each file is examined just with a single processor core. v0.7.0-dev changes this and instead scans files in parallel, one file per CPU core. This speeds up the initial load time in many cases (and slightly slows it down in others - it’s definitely a trade-off).
There are still a few instances where parallel scanning isn’t used, such as with
the new --vgm-strict-gd3-loading option. In those cases, Benben v0.7.0-dev
just falls back to doing the older style serial pre-scanning. But most of the
time, it’ll scan files in parallel.
I’m 95% sure that I’ll leave parallel scanning in as the default behavior by the time v0.7.0 comes out since, in my personal experiences, it seems to be worth the trade-off.
DC Filter Added
Benben v0.7.0-dev has a new effect: a DC
offset removal filter. This is
enabled by default since it has no effect on performance, but can be toggled
with the d key during playback, and can also be disabled in your configuration
file with dc-filter: false.
SIMD Added
One nice thing about moving Benben’s code to Common Lisp: first-class SIMD support. Well, on x86-64 platforms, anyway.
With one big exception (see the section about AppImages below), as long as your CPU supports the needed instruction set extensions, Benben will now use SIMD code (mainly AVX and AVX2 instructions) in various places to speed up calculations. On CPUs that don’t support the necessary instructions, or on non-x86-64 CPUs, Benben transparently falls back to its older calculation code.
AppImage Changes
I’ve made it a point to provide AppImages of Benben since day one because:
- I don’t want to (or can’t) provide true statically-compiled binaries.
- Not everyone knows how to build software from source.
- Even fewer people know how to build Crystal software, or have access to the compiler.
- Even fewer people know how to build Common Lisp software, or how to set up their environment to do so.
- I wanted to learn how to do AppImages.
Older versions of Benben’s AppImages targeted (or intended to target) CPUs that came out around 2008) as a minimum requirement. This seemed like a good trade-off at the time since that was (now) 27 years ago, and it allowed the Crystal compiler to use SSE instructions to speed up certain pieces of code.
…I say “intended to targe” because, for a while, I was accidentally building AppImages that targeted slightly newer CPUs 😅
Anyway, up until now, I’ve built AppImages in a QEMU virtual machine set to virtualize a Nehalem CPU, running Slackware Linux 14.2. This was chosen for three reasons:
- I’m extremely familiar with Slackware, having used it almost exclusively since 2002.
- Slackware 14.2 uses an old glibc version, which is important for producing AppImages that run on the widest variety of systems possible.
- The Nehalem-era CPUs are as old as I’m willing to officially support.
Unfortunately, the move to Common Lisp and the introduction of SIMD code has brought with it an unexpected hiccup: I can’t build AppImages that support SIMD on Nehalem.
I mean, I can… but not in a way that I want. When it comes to Common Lisp, I always build the compiler, SBCL, from source so that I can ensure it includes features such as the SB-SIMD package that I use for SIMD support. But, I’ve discovered that if I build it in a VM running a Nehalem-era CPU, it refuses to build SB-SIMD. I can’t even build a subset with support for just SSE4.2. What’s more is that the pre-built SBCL binaries won’t even run on this CPU. It’s only when I increase the CPU level to something that supports AVX2 instructions (e.g., Intel Broadwell) or newer) that I can build SBCL with SB-SIMD.
That leaves me with a quandry: build AppImages without any SIMD support at all, or increase the minimum CPU required for my AppImages.
I’ve decided to do both.
So, starting with v0.7.0, there will be two different AppImages available: an
SIMD-enabled version named benben-0.7.0+avx2-x86-64.AppImage, and a somewhat
slower version for older CPUs named benben-0.7.0+older.cpus-x86-64.AppImage.
Development AppImages will only be available as the SIMD versions, however.
Revamped Build System
The old Rakefile-based build system has been ditched since Common Lisp already has its own build system called ASDF. And whew, is it a breath of fresh air! I forgot just how much I positively love ASDF and wish other languages had something as nice as it.
Anyway, v0.7.0-dev and all its support libraries use ASDF. Then, to make it
easier for non-Lisp users to build a binary, a build.sh script is also now
provided. Some preliminary
instructions
are provided for building the Lisp binaries (this file will eventually disappear
and become an actual wiki page in the repo by the time v0.7.0 is released).
Resampler Default Changed
The default mode for the resampler has been changed from sinc-fast to
linear. This change was done for a few reasons:
- The practical quality difference between
linearandsinc-fast(orsinc-mediumorsinc-best) is very small. I don’t even notice it, even after many, many hours of listening to both. And while I’m sure there are a few cases where it’s noticeable for some people, I’m thinking the average listener won’t notice the difference. - The
linearmode is much faster and easier on RAM. - Users who want to use the sinc resamplers can still do so with the
--resamplercommand line option, or via their config files.
This change won’t affect you if you already have the resampler mode changed in your config file.
What to Expect From v0.7.0
That’s all the new stuff that got added since last month. See? I told you it was a lot! ^_^;
Anyway, what’s the overall expectation by the time Benben v0.7.0 comes out? Well, aside from new features that I haven’t yet started to work on, you can expect this:
- Benben v0.7.0 will still feel like Benben, because it is still Benben.
- Benben v0.7.0 will play all the same formats as it plays now, plus the new Extended QOA Format.
- Some formats will use less CPU (FLAC and QOA, when not resampling).
- Some formats will use about the same amount of CPU when they aren’t resampled (mp3, WavPack, modules).
- Some formats will use a bit more CPU (VGMs, anything that needs resampling).
- The program will respond a lot faster to
remote-benbenmessages. - There will be the usual set of bug fixes, but there may be new and unexpected bugs that were accidentally introduced during porting.
- The VU meter is a lot more responsive and matches what you’re hearing better (I think maybe the Crystal version had some weird delay thing going on in the runtime?).
- Benben v0.7.0 will start up faster in many cases, but may start up just slightly slower in a few others. The end-user impact will be minimal, regardless.
- Benben v0.7.0 will use a bit more RAM because Common Lisp’s runtime is simply different than Crystal’s runtime. It’s complicated¹.
What I’ll Be Focusing on Next
Benben v0.7.0-dev is at a point where I’m already using it as my daily music player, but don’t let that fool you. There’s still a lot left to be done before v0.7.0 is ready. But, after such a busy and frenzied April, development from here on out will probably come more in “spurts” while I shift my focus to the various support libraries.
For one, adding MIDI to Benben necessitates that I first update my old, somewhat-neglected CL-MeltySynth code and get it up to the same level as my Haematite library for Crystal. Thankfully the code isn’t too far off, but there’s some major things missing from CL-MeltySynth, like mmap()‘ed SoundFonts to reduce memory usage. I’m also going to see about fixing a few bugs in both codebases that have popped up as tickets.
Then there’s Vorbis… older versions of Benben simply used some Crystal bindings I wrote for libvorbis, but this library doesn’t really play well with SBCL because of how the Common Lisp runtime interacts with foreign threads. To get around this, I’m either going to have to write bindings for stb-vorbis, or I may take some time and hand-port stb-vorbis to native Common Lisp. Currently I’m leaning towards hand-porting the code since that’s just my way of doing things, but I’m not 100% sure on this yet.
Aside from that, I also need to get the VGM support closer to being feature-complete so that I can start looking at new ways to optimize it for Common Lisp. One idea I’m currently playing with is to remove the resampling code from SatouSynth, which was code that came from VGMPlay, and replace it with the code in CL-RemiAudio so that I open up more opportunities for SIMD within the emulator cores themselves, as well as simply call into them less frequently to fill buffers (the current code calls the emulator cores very often, filling a buffer with just one or two samples at a time - this doesn’t play well with Common Lisp²).
And finally… Extended QOA Format. I plan to formally introduce it in a blog post as soon as I finish up the command line tool to encode/decode/tag/modify/etc. XQA files.
So, I’ll probably focus on SatouSynth’s emulation cores and MIDI stuff for a while, and XQA stuff.
Footnotes
Measuring memory usage isn’t as straightforward as opening htop or your System Monitor and looking at the memory column. Because of things like shared libraries, mmap()‘ed files, swap, etc., the number you see in the memory column isn’t necessarily the absolute truth, and it’s hard to arrive at an absolute truth.
The two monitors I use the most are htop and Evisum, and they routinely differ in what they report for each program’s “memory used” because of how they calculate it. In brief, if you subtract the “SHR” column from the “RES” in htop, you get close to the value that Evisum reports. This is probably because RES is the size of the program’s text, data, and stack in memory, while SHR is pages that are shared with other programs and mapped with mmap(). Evisum seems to take the approach that subtracting it gives you a more accurate number as that number is “only what’s unique to that program”. At least that’s my best guess as to its reasoning ^_^;
This is complicated by how Common Lisp works: it uses image-based programming similar to Smalltalk, where the state of the program is saved as a “core” image. Loading a core file loads the program back into memory and puts you back where you left off, kinda like a save state in a console emulator. The runtime for Common Lisp is also stored as an image in a “core file”, and when you start the Common Lisp REPL, it loads this core into memory. Or, in the case of SBCL (and this is important), it mmap()’s it (at least I’m almost sure it does).
When you write Common Lisp code, it gets compiled (SBCL and many other modern Common Lisp implemenations compile it to native machine code). and this compiled code gets stored in RAM until you write it out in an image. An image is even created when you create a binary of a Common Lisp program: it simply writes out a very small loader program called the kernel, then appends the core image onto it. This core includes the entire Lisp runtime, compiler, and all code. This is why 1) you can’t strip Common Lisp executables without ruining them (it removes the core), and 2) Common Lisp binaries are rather large.
Why am I mentioning this? Because when I open up htop and see Benben v0.7.0-dev using 100mb of RAM, I have to mentally remind myself that the vast majority of that number is the mmap()‘ed core image, and most of it is probably still on disk rather than in-memory. So when I look at the memory usage of my Common Lisp programs, I tend to look at htop, then at Evisum, and then figure it’s probably a number in-between the two.
As I said above, it’s complicated.
Common Lisp is a strongly typed, dynamic programming language. You can add static type information all over the place to increase performance (I probably do this a bit too liberally, but whatever, no harm done), but at the end of the day, it’s still a dynamic language.
It’s also a language that can be modified as it runs, either by its own code, or by the programmer connecting to a running Lisp program. Because of this, function calls are expensive: the program always has to be sure it’s calling the correct bit of compiled code. This is called a “full call”.
The exceptions are inline functions, and functions that are defined in special blocks like LABELS and FLET. These can be compiled to what’s called a “local call”, which is much faster than a full call.
SBCL is a descendant of an older implementation called CMUCL, and one thing it inherited from CMUCL is “block compilation”. It essentially lets the compiler use local calls instead of full calls.
SatouSynth uses block compilation a lot. Heck, most code I write uses it whenever possible. But, as far as I know, block compilation can’t be applied across source files. Since it would be absolutely absurd and unworkable to put all emulation cores plus the VGM playback code into a single file, every call in SatouSynth to get new audio from a chip’s emulation core ends up being a full call.
In truth, this is actually more because the code is a (mostly) straight port of YunoSYnth’s code, and by extension, VGMPlay’s code, where the internal resampling code calls the emulator cores repeatedly, each time asking only for one or two samples (I forget off the top of my head). This was fine in Crystal and C since they don’t really have the issue of full calls vs local calls.
So, to get around this, my idea is to swap out SatouSynth’s resampler code with the resampler I have in CL-RemiAudio, then have it function in such a way that it asks the emulation core for entire blocks of audio data, not just one or two samples. In Benben’s case, this would mean 256 samples at a time. That’s 254 fewer full function calls. Hopefully you see where I’m going with this…
As a side effect, SatouSynth would actually have a much higher quality resampler with multiple modes of operation - CL-RemiAudio’s is a port of libsamplerate! XD